… però mi sorge qualche dubbio:
con l’SSD (che ha preso il posto del disco morente) collegato alla M.B. ottengo questo:
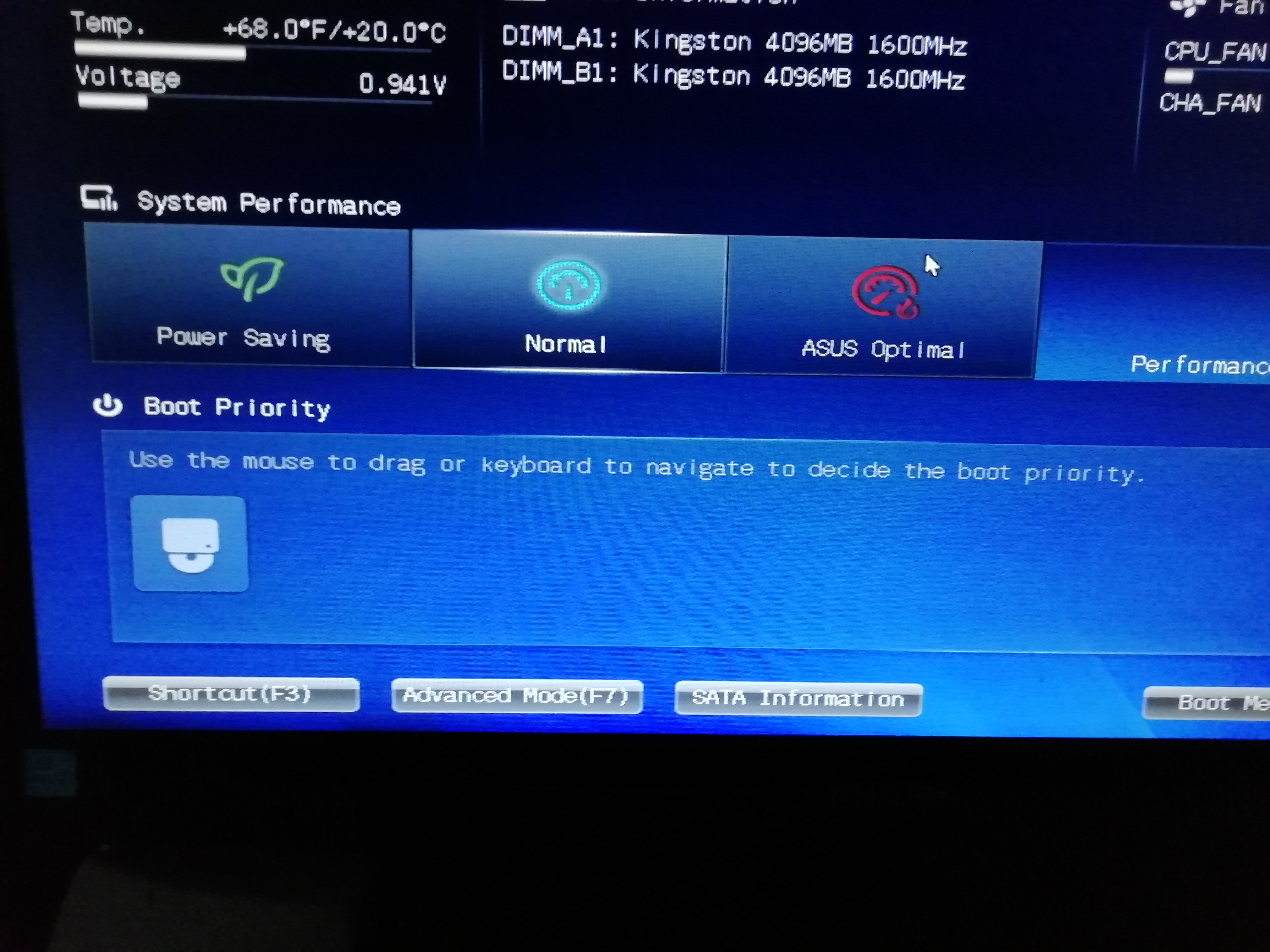
è visibile solo il lettore ottico.
Provando a collegare l’SSD tramite la porta USB ottengo, mi pare casualmente, una delle due situazioni:
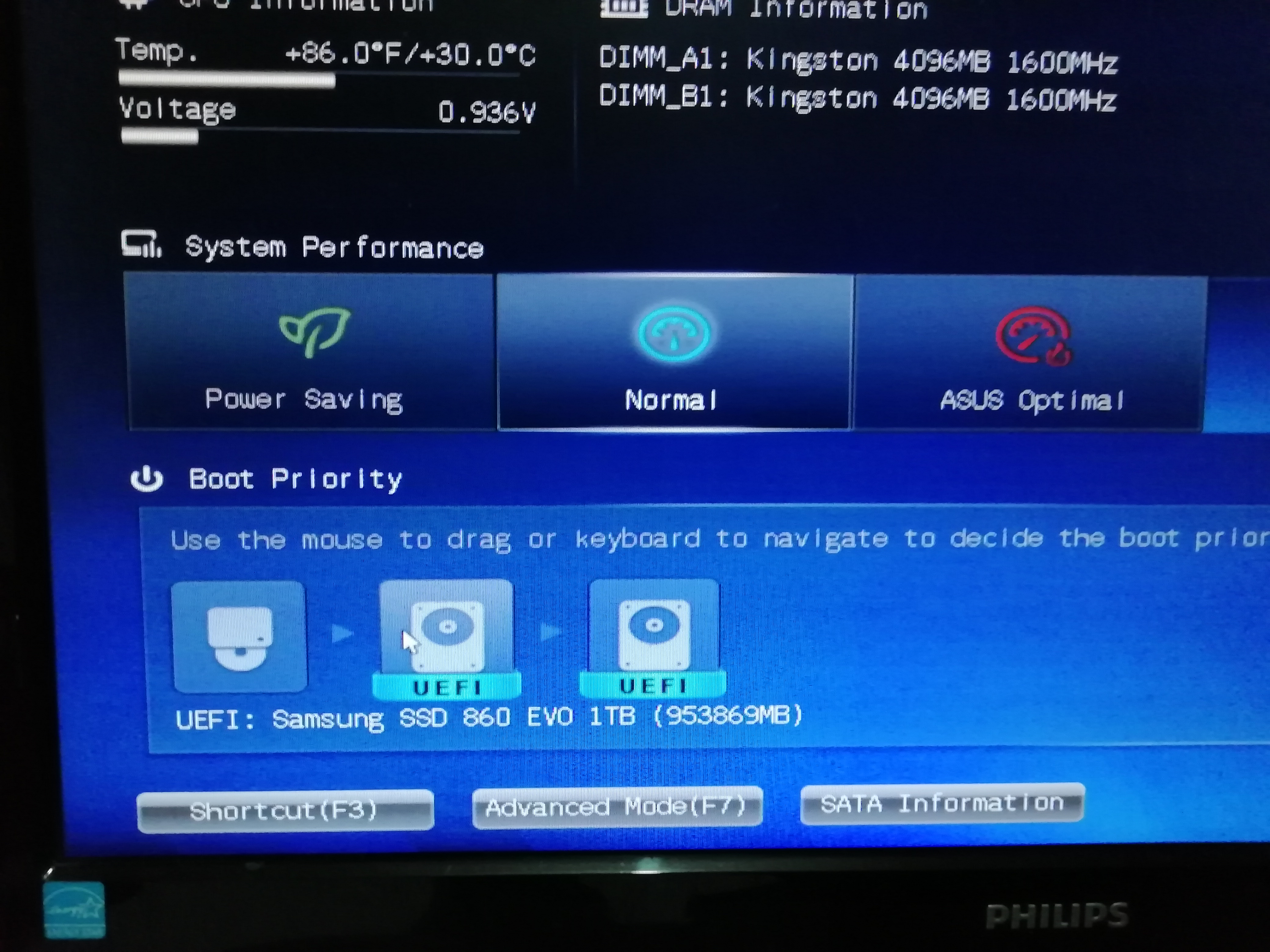
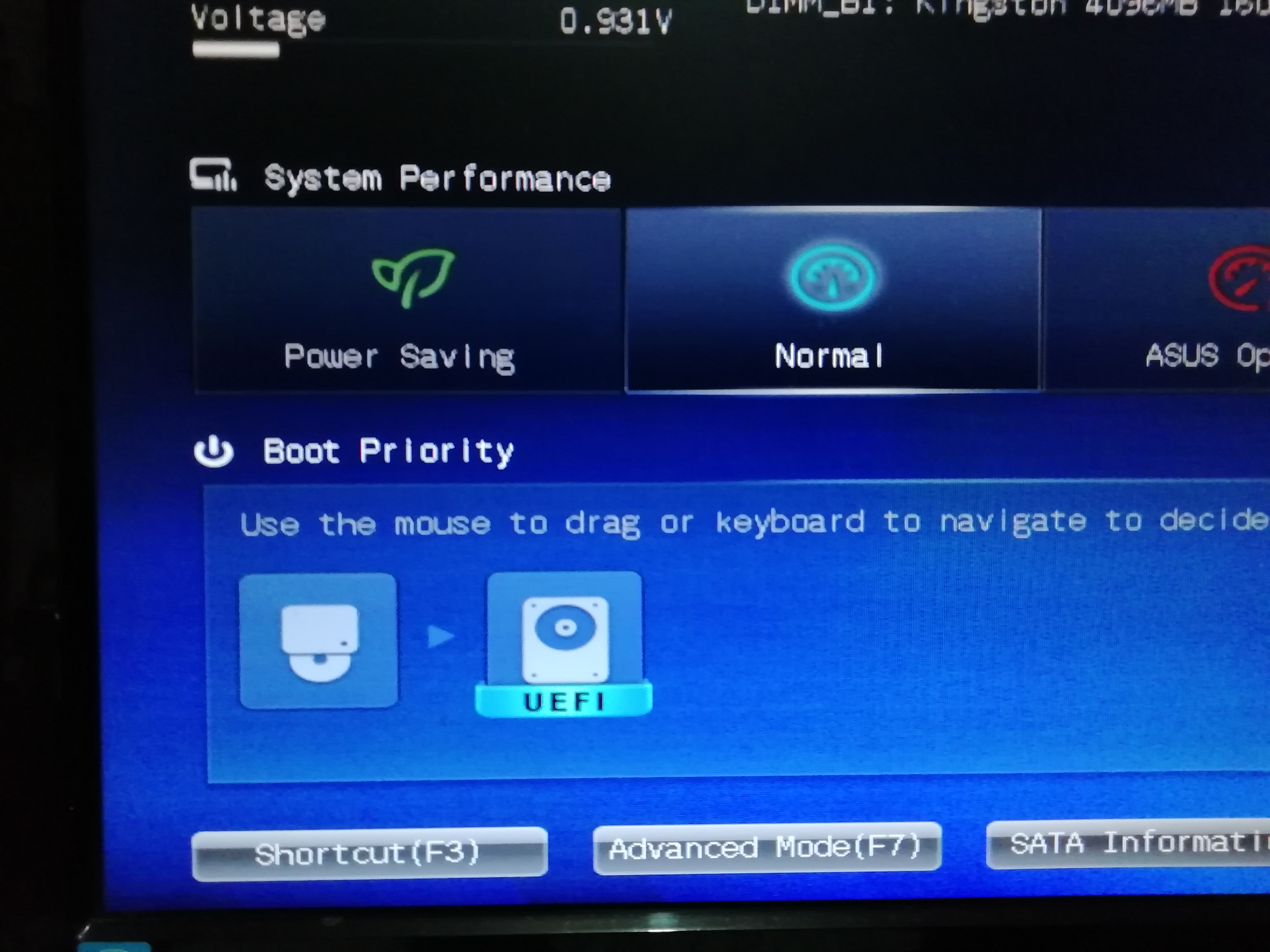
Tutte le icone UEFI sono riferite all’SSD.
Ho anche provato ad avviare dall’SSD collegato alla USB ma non funziona.
Quindi, ha senso ricostruire GRUB se il Bios/UEFI non vede l’SSD per il boot?
Grazie.